


Since September, GPT-4, a powerful language model released by OpenAI, has included a model with the capability to view images called GPT-4V. OpenAI states that these models can “solve new tasks and provide novel experiences for their users” by translating information from images to text, the opposite of models like DALL-E 3.
OpenAI revealed the initial text-only model of GPT-4 in March of this year. A paper by Microsoft titled “Sparks of AGI” predicted that this model exhibited “sparks” of artificial general intelligence, the name for a hypothetical model which could match humans in all intellectual tasks. This paper exhibits GPT-4’s ability to write and create programs, as well as its spatial knowledge, which allows it to draw basic figures. However, this model was not a multimodel. It “drew” the aforementioned figures manually using code, rather than with more sophisticated image generation models that have emerged. An OpenAI article on GPT-4’s capabilities demonstrates its proficiency in the Bar Exam, the SAT, and several AP tests, but states that a version with vision performed slightly better in some tests than a version without vision.
Yet, OpenAI did not release the version of GPT-4 with vision until months after the release of the visio-less version. OpenAI was concerned that AI with vision could violate the privacy of humans by identifying faces. Using biometric information without permission is illegal in somer jurisdictions, such as Illinois and the European Union. This boundary on GPT-4’s abilities has limited the ability of one startup called Be My Eyes. The startup collaborated with OpenAI to create Be My AI, a tool that explains visual information about surroundings to blind people. After a beta test, the startup confirmed that Be My AI would be an invaluable tool for the blind, but some users expressed frustration over the app’s inability to describe faces.
In September, OpenAI announcing that they were rolling out the ability for ChatGPT to “see, hear, and speak”. It can now converse with users and analyze images; the positive feedback to Be My Eyes influenced OpenAI’s decision to roll out vision. However, the current model still cannot analyze faces due to OpenAI’s restrictions.
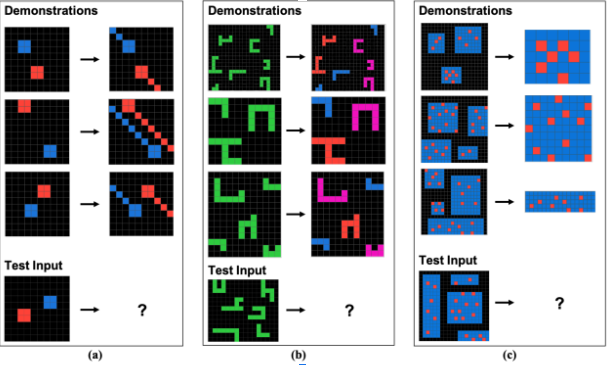
Despite GPT-4V’s strengths, it is not at the level of an AGI. A study by Mitchell et al. showed that the model performed much worse at abstract visual tasks than humans. The models are weak at reasoning outside their fields; this has led some researchers to believe that large language models (LLMs) learn complex patterns in their data sets rather than learning abstract reasoning. It is currently unclear whether LLMs can create “human-like abstractions”, according to the paper.
GPT-4V, along with multimodel models such as Google’s Bard, have clear potential to benefit the world with their visual capabilities, but their technical limitations and the risks they pose to privacy illustrate that human-like intelligence in AI is not yet here.

















